こんにちは。2022年7月に入社したサーバーサイドエンジニアの青山です。
今回は入社してからやってきたことの1つとして、同じグループの山田と一緒にAmazon RDSのPerformance Insightsを利用してアプリケーション側からDBの負荷を改善した話をします。
※改善するにあたり複数の対応をしましたが個々の対応の詳細については書いていないのでご注意下さい。
はじめに
Studyplusはサービスの性質上、受験シーズンにかけてユーザー数や利用頻度が増加していく傾向にあります。そのような背景もあり、私が入社して数ヶ月が経った頃から徐々にDBへの問い合わせでタイムアウトエラーが発生するようになりました。
また、タイムアウトエラーが発生するタイミングでDBのCPU負荷が上昇していることをDatadogからの通知で観測できていました。
そこで、DBのCPU負荷が上昇することでDB側の処理が詰まった結果、タイムアウトエラーを引き起こしているのではないかと考え、DBの状況から調査することにしました。
Performance Insightsを利用して調査
タイムアウトエラーが発生していたアプリケーションはDBにAurora MySQLを利用しており、Performance Insightsが有効だったため、そちらを利用して調査することにしました。
Performance InsightsはAmazon RDSの機能の1つで、データベース負荷やトップSQLなどDBのパフォーマンスに関わるメトリクスを確認できます。
データベース負荷の確認
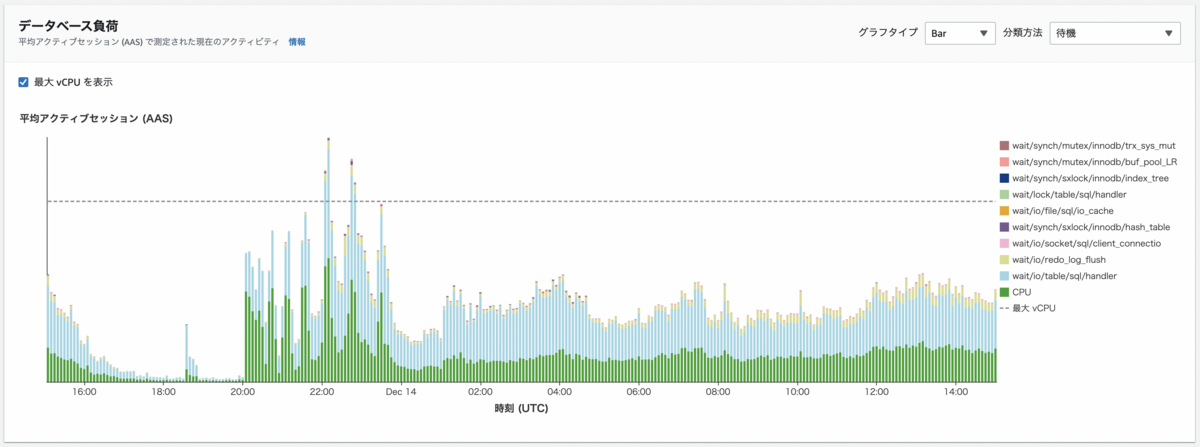
以下の画像は負荷が高かった時間帯のデータベース負荷のグラフです。
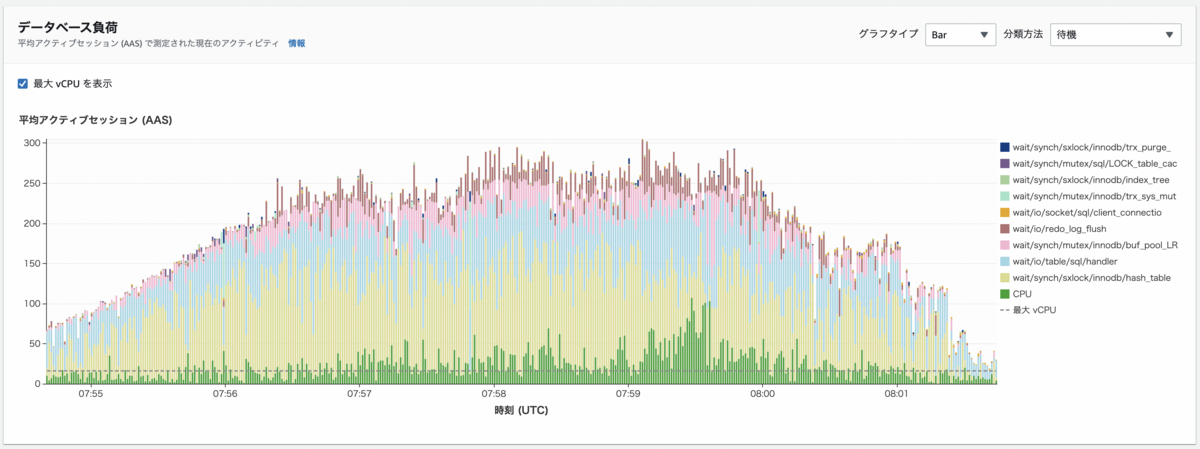
上記の画像では、平均アクティブセッションが最大vCPUのラインを大幅に超えているので、DBの処理が詰まってDBのパフォーマンスに影響しているであろうことが分かります。
vCPU では一度に 1 つのプロセスを実行できます。プロセスの数が vCPU の数を超えると、プロセスはキューイングを開始します。キューイングが増加すると、パフォーマンスに影響します。
また、Aurora MySQLであれば各待機イベントの原因や対応例については 待機イベントを使用したAurora MySQLのチューニング などで確認できます。
トップSQLの確認
以下の画像はデータベース負荷の画像と同時刻帯のトップSQLです。
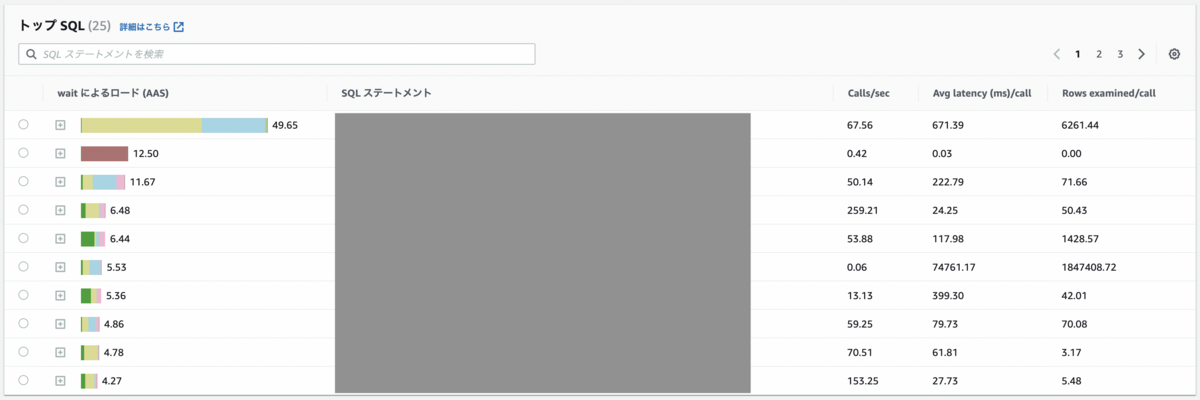
上記の画像では、1番目のSQLステートメントが待機イベントの大半を占めていてボトルネックになっていそうなことが分かります。
また、SQLステートメントの右側にある項目から以下のことも読み取れるので参考になります。
- Calls/sec
- 1秒あたりにクエリがどのくらい呼び出されているか
- Avg latency (ms)/call
- 1回のクエリの呼び出しにかかる平均時間
- Rows examined/call
- 1回のクエリを呼び出すのにデータを何行見にいったか
ボトルネックの解消
Performance InsightsからボトルネックとなっていそうなSQLステートメントをいくつか知ることができたので、対応した時に効果が大きそうなものから以下のような対応をしました。
- 最適化の余地がありそうなものはクエリを最適化
EXPLAINで実行計画を確認- プロダクトオーナーと相談して仕様から調整
- 更新がほとんどないデータを高頻度で呼び出すクエリは一定間隔でキャッシュ
- 調査した結果、既に不要になっていたものは処理自体を削除
- N+1の解消
改善した結果
まず、今回の課題であったタイムアウトエラーが発生しなくなりました。
その他にも以下のような成果を得られました。
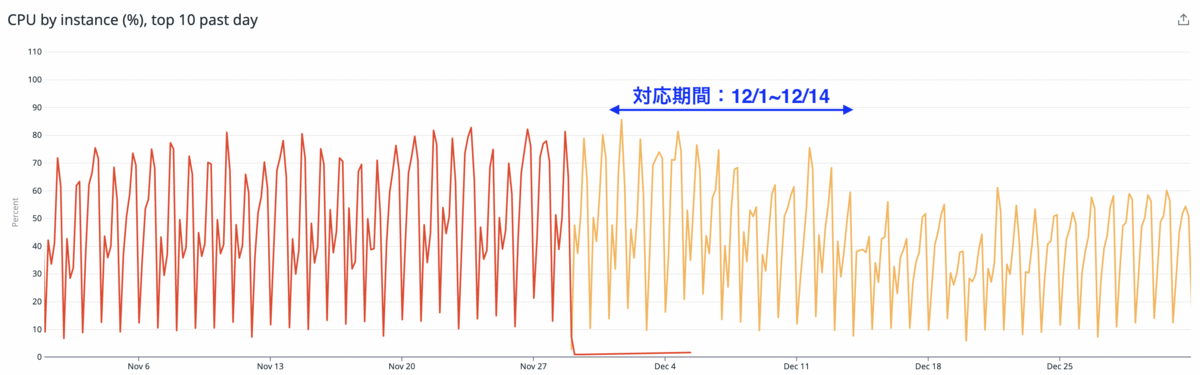
DBのCPU負荷削減
元々80%前後で推移していたDBのCPU負荷は60%前後まで減らせました。
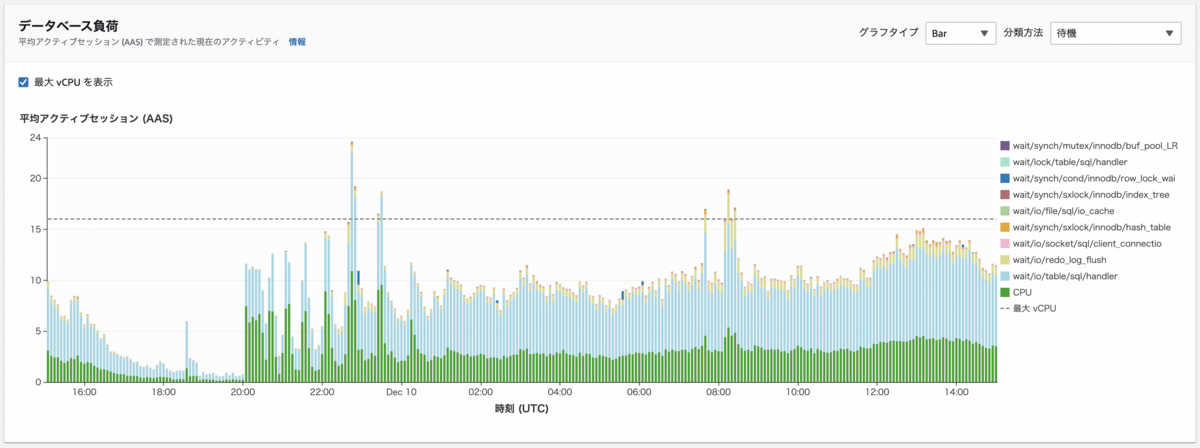
データベース負荷削減
全体的に平均アクティブセッションが減り、ピークタイムに最大vCPUを超えないようになりました。
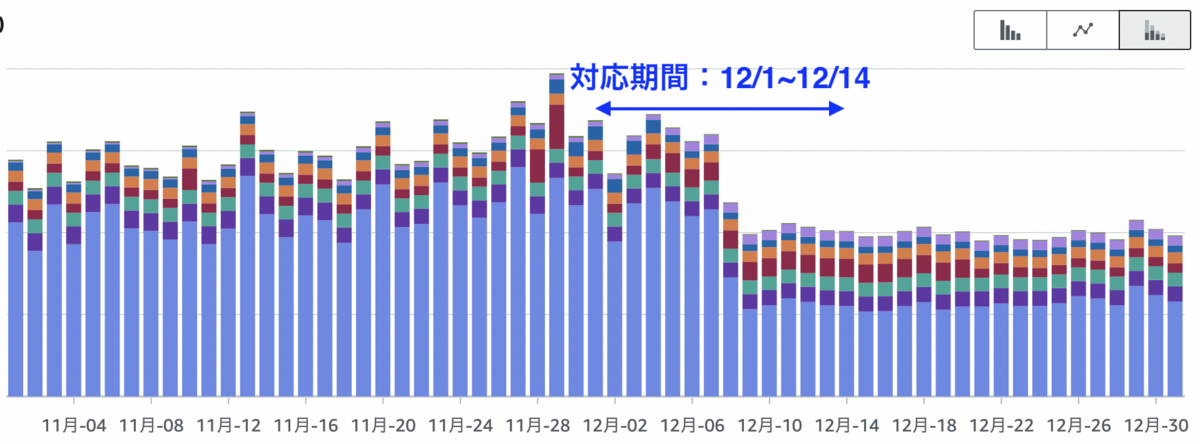
Amazon RDSの費用削減
嬉しいことにAmazon RDSの費用も減り、12月は前月と比べて22%程度削減されました。
おわりに
発生していたDBのタイムアウトエラーはユーザー影響があるものだったので、今回の対応で一定の効果が得られて良かったです。
また、Performance Insightsのようなモニタリングツールを使ってメトリクスを確認し、計測された値からボトルネックを把握することの大切さを改めて感じました。
まだまだ改善の余地はありそうなので、今後も隔週で行っている改善デーなどの時間を利用して対応していけたらと考えています。