Karpenter導入によるメリットとデメリットと躓いた点
こんにちは。SREグループの蜂須賀です。
弊社ではEKSを利用しており、これまでノードのオートスケールにはCluster Autoscaler(CA)を利用していました。
2024年6月頃にCAからKarpenterに移行したので、Karpenter導入によるメリットとデメリット、躓いた点を紹介します。
(Karpenterのバージョンはv0.37になります)
Karpenter導入によるメリット
ノードの起動速度が速い
CAでは、Amazon EC2 Auto Scalingグループを経由してノードのスケーリングを実施します。
Karpenterは直接ノードのスケーリングを実施するため、Auto Scalingグループを経由しない分だけノードの起動が早くなります。
実際に、nginxの1Podを起動要求してから、新ノードを追加して、nginxの起動が完了するまでを計測しました。
以下のように、Karpenterの方が23秒ほど早く起動される結果となりました。
Karpenter:36s CA(Cluster Autoscaler):59s
ノードのリソース効率の向上
CAでは、スケールインされるには主に以下の条件に該当するノードが必要となります。
- ノード上の全Podのリソースリクエストの合計が、ノードに割り当てられたリソースの50%未満
- ノード上の全Podを、他のノードに移動できる
Karpenterでは、ノード上の全Podを他のノードに移動できるのであればスケールインが実施されるため、ノードのリソース効率が向上します。
Karpenter導入によるデメリット
Karpenter用のサーバコスト
Karpenter自体のPodは、Karpenter管理外のノードにデプロイすることが推奨されています。*1
また、冗長化の観点からKarpenterは2つのノードにそれぞれ1つのPodを配置することが望ましいです。
CAからKarpenterに移行するにあたり、Karpenter用のノードを2つ増設する必要がありました。
Spotインスタンスの中断通知への遭遇率が高くなる
Spotインスタンスの中断通知を受け取ったノードは、2分以内にPodを安全に終了させなければいけません。
CAはAuto Scalingグループを使用しているので、キャパシティリバランシング機能によって中断リスクの高まったスポットインスタンスを事前に交換してくれます。
Karpenterではキャパシティリバランシング機能がないため、中断通知に遭遇する機会が高まります。
そのため、Karpenterを使用する場合は、Spotインスタンスの中断通知への対応をより厳格にする必要があります。
Karpenter導入で躓いた点
ノードの最小台数設定ができない
CAではノードの最小台数の設定が可能ですが、Karpenterでは設定できません。
弊社ではSpotインスタンスの中断処理に対応するため、最小台数を設定したい事情がありました。
この問題に対応するため、dummy-podを作成することで最小台数を設定をできるようにしています。
以下のdummy-podは1ノードに1Podしか配置できない設定になっているので、dummy-podのPod数分のノードが必ず生成されている状況を作ります。
apiVersion: apps/v1
kind: Deployment
metadata:
name: dummy-deployment
spec:
replicas: 2 #ノードの最小台数設定
selector:
matchLabels:
name: dummy-pod
template:
metadata:
labels:
name: dummy-pod
spec:
containers:
- image: public.ecr.aws/docker/library/busybox:latest
imagePullPolicy: IfNotPresent
name: dummy-pod
command: ["sleep", "infinity"]
terminationGracePeriodSeconds: 10
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
labelSelector:
matchExpressions:
- key: name
operator: In
values:
- dummy-pod
想定通りスケールインが発生しない
導入試験中に本来スケールインされる状態でスケールインが実施されないケースにあたりました。
推測の域ではありますが、KarpenterはtopologySpreadConstraintsの設定がScheduleAnywayであろうと、topologySpreadConstraintsの条件を満たせる時のみスケールインをします。
例えば、Deploymentに以下のようなノード分散の設定をして、2ノードに1Podずつ配置されている場合、リソース的に余裕があってもスケールインされませんでした。
topologySpreadConstraints:
- topologyKey: kubernetes.io/hostname
maxSkew: 1
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
name: pod
おそらくPodを移動するとmaxSkewの値を超えるためにPodが移動できないと推測されます。
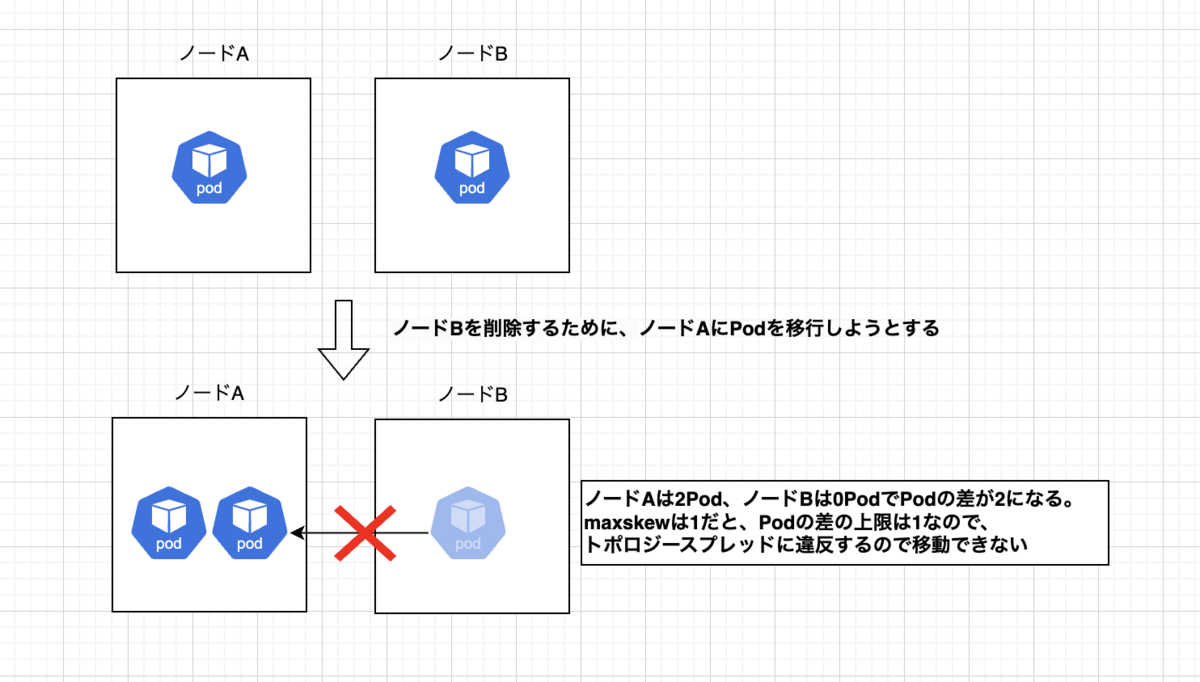
上記の場合ですと、maxSkewを2に変更するとスケールインが実施されました。
Karpenterを導入する際は、topologySpreadConstraintsの設定の見直しを実施しないとノードのリソース効率が悪くなるので注意が必要です。
まとめ
Karpenterを導入することでノードのリソース効率が上がりますが、Karpenter用のサーバコストも発生するので、ノードのスケーリングがあまり発生しないような環境ではCAを利用する方が良いと考えられます。
弊社では、ノードのスケーリングが頻繁に起きるため、Karpenterを導入したおかげでノード効率が向上しEC2コストを抑えることができました。
また、移行しただけでは逆にノードのリソース効率が下がることもあるので、導入の際にはKarpenter用に設定の見直しをする必要があります。