こんにちは。サーバーサイドグループの五十嵐です。
最近のマイブームはキャンプギア集めで日々キャンプ動画を漁っています。
今年は登山もやってみたいなと思っているのですが、在宅ワークでほぼ動かない生活をしているので足腰を動かすために毎日ウォーキングするように心がけています。
思い立っては運動し、続けようと頑張っては三日坊主になってを繰り返しています。
はじめに
機能開発が進んでいく中で名前が実態に合わなくなってくることはよくあります。
メソッド名やカラム名などは影響範囲が少なく割と気軽に変更できるため修正することで対応できます。
しかしテーブル名になってくるとかなり大変です。
モデル名と関連のkeyをRails側で調整することは可能ですが、正しい名前が使われていないことで長い目で見れば負債になっていきます。
開発段階ならばアプリに大きな影響がないため問題なく変更ができますが、既存機能で日々使われているテーブルですと変更に大きなリスクが発生するため、テーブル名変更時はサービスを停止して実行することでそのリスクを小さくします。
しかし、弊社のアプリは受験生が多く利用しているため、受験シーズンでは特にサービス停止をしないように最大限心がけています。
今回の対応はちょうど受験の天王山である夏休み期間に行われることになったため、ユーザーがいかなる時間でもサービスを安心して使っていただけるようにサービス停止をしないでテーブル名を変更しようということになりました。
今回はそのサービス停止を伴わずにテーブル名変更した手順について紹介します。
環境
- フレームワーク: Ruby on Rails
- データベース: Amazon Aurora MySQLのMySQL8.0系互換
前提
今回の手法はテーブル名を変更するというよりもテーブルを移行するという方が正しいかもしれません。
サービス停止を伴わずに直接テーブル名変更する場合はほぼ間違いなくエラーが発生します。
テーブル名変更を行なっている間、レコード作成や参照するときにサービス内で古いモデル名やテーブル名が使用されるためです。
これを回避するために今回とった手法が別テーブルを作ってデータをコピーし最後に切り替えるという手法です。
この手法のメリットは最後に切り替える時まで既存のサービスには大きな影響が発生せず、安心して作業を行えるという点です。
今回テーブル名変更を行なったテーブルはユーザーが直接レコードを作ることがない(いわゆるマスターテーブルな)ためユーザーがレコードを直接作成できるテーブルの場合は違った手順が必要になるかもしれません。
あらかじめご了承ください。
以下テーブル名変更をしたいテーブルをテーブルA、変更後のテーブル名をテーブルBとして記載していきます。
対応手順
以下におおまかな手順を書きます。
詳しくはそれぞれの項目で説明していきます。
- テーブルAと依存関係のあるテーブル(テーブルC等)にテーブルBのidを持たせるためのカラムを追加
- テーブルAと同じテーブル構造でテーブルBを新規作成しデータをコピー
- テーブルAを使用している箇所全てをテーブルBに書き換え
- 後片付け
テーブルAと依存関係のあるテーブルにテーブルBのidを持たせるためのカラムを追加
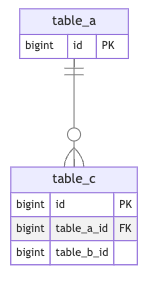
テーブルAと依存関係にあるテーブルにはすでにtable_a_idのようなテーブルAのIDを持つカラムが存在するはずなので、変更後のテーブルBについても紐づけられるようにあらかじめカラム(table_b_id)を用意しておきます。
また、カラムを用意した後にはレコード作成・修正時もtable_b_idにtable_a_idと同じ値が入るように修正し、既存レコードにおいてもtable_a_idの値をtable_b_idにコピーしていきます。
table_b_idにtable_a_idと同じ値が入るような修正ではrailsのコールバックを利用しました。
before_saveで設定しておけば保存時にtable_a_idの値を入れてくれるため便利です。
コピーよりも先にコールバックの設定を入れておくことでコピーとコールバックの実装反映のタイムラグで意図しないレコードができることを防ぎます。
テーブルAと同じテーブル構造でテーブルBを新規作成しデータをコピー
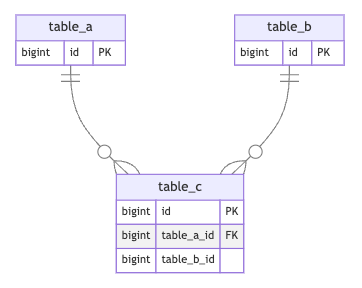
テーブルをクローンする場合、私が思いついた選択肢は2つありました。
1. テーブルコピーと同時にレコードコピーのパターン
2. 先にマイグレーション等でテーブルを用意した後にレコードをコピーしていくパターン
結果的には2の「先にマイグレーション等でテーブルを用意した後にレコードをコピーしていくパターン」を取りました。
1. テーブルコピーと同時にレコードコピーのパターン
SQLを実行すればテーブルコピーとレコードコピーを同時に行うことができます。
CREATE TABLE table_b SELECT id, name, created_at, updated_at FROM table_a;
このSQLで作成されるテーブルBにはいくつか問題点があります。
大きな問題点はprimary_keyの設定がなくなっていることでここでは詳しく触れませんが自分で設定し直す必要があります。
また、テーブルAにあったindex等もテーブルBには引き継がれません。
SQL一発でレコードまでコピーしてくれるのはとても楽なのですが、テーブル構造まで全く同じにできるわけではないためこちらの方法は選択しませんでした。
2. 先にマイグレーション等でテーブルを用意した後にレコードをコピーしていくパターン
こちらの方法では、先にマイグレーションを実行しテーブルを用意してあげるため、テーブルAと同じ構造でmigrationファイルを作成してあげれば同じ構造のテーブルができます。
primary_keyやindexもmigrationファイルに書いた通りに作られるため安心して作業ができます。
テーブルを作成した後はrakeタスクでレコードを作って行っても良いしSQLで作成してもいいです。
レコードが多い場合はSQLで実行した方が早いし簡単です。
INSERT INTO table_b SELECT id, name, created_at, updated_at FROM table_a;
コピーした後はレコードの数が一致しているか、index等が機能しているか、auto_incrementが一致しているか等を確認します。
auto_incrementの一致は以下のように調べられます。
SELECT TABLE_NAME, AUTO_INCREMENT FROM information_schema.TABLES WHERE TABLE_NAME IN ('table_a', 'table_b')
| TABLE_NAME | AUTO_INCREMENT |
|---|---|
| table_a | 100 |
| table_b | 100 |
テーブルAを使用している箇所全てをテーブルBに書き換え
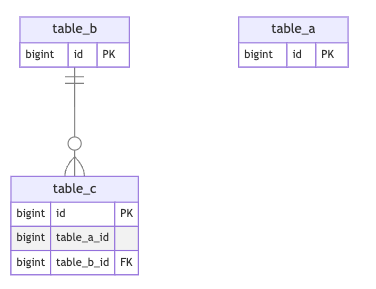
テーブルに紐づいているモデルやそのコントローラー、テストなどソースコード上で使っている箇所を全て漏れなく書き換えていきます。
漏れがあるとエラーになるので自動テストだけでなく周辺機能は手で動かしてチェックすることをおすすめします。
この修正を本番にデプロイすると完全にテーブルBに切り替わるので慎重に行いましょう。
テーブルAと依存関係にあったテーブル達のテーブルAへの外部キー制約を外し、テーブルBに付け替えておくことも忘れないようにしましょう。
これでテーブル名変更の主なタスクは終了です。
後片付け
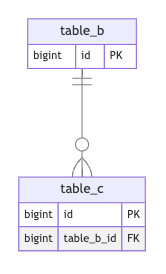
ここでは不要になったテーブル・カラムを最後に削除していきます。
テーブル削除する前に何かあった時用のダンプをとっておくと安心です。
まとめ
以上が私が今回行ったサービス停止を伴わないテーブル名変更の方法です。
もちろんサービス停止できる状況であれば停止して作業する方が絶対に安心です。
少しでも参考になれば幸いです。